
Processing Video with MediaConvert and Lambda
Story Time: So one day I’m just sitting at my desk and my manager gets all up in my business with “Yo, you with the face. Come with me.”
He takes me across the carpark to another building where I get introduced to one of our developers. We have a chat about a project he’s been working on. It takes a GoPro video, runs each frame through a machine learning algorithm, and spits out a JSON file at the end.
Some pretty awesome shit.
Unfortunately going frame-by-frame each video ends up taking a while. The dev will load up a queue on Friday and let it run over the weekend.
Bossman starts turning starfish shaped and says “we should take this project, and push it somewhere else.” Naturally, by Somewhere Else he meant AWS. And by We he meant me.
So I did.
The goal here was to reduce the time it takes to process a video, likely by processing frames in parallel. Ideally we’d toss them in Lambda triggered off EventBridge when the frame shows up in S3. The alternative would be to just chuck it in EC2, but that would run into the same compute limitations we had with the physical hardware.
Now don’t get me wrong, this wasn’t easy. First thing was to get the processing into Lambda. Of course the whole thing was way too large. Tensorflow itself wouldn’t fit in Lambda at the time. Even once we got that sorted, the issue relevant to this post was how to split the video into frames.
Splitting a video into frames isn’t actually too hard. You could do this in Python with OpenCV, or from the CLI with FFMPEG. Our real problem was getting enough ephemeral storage in Lambda to stash not only the source video, but also each of the 65k frames that make it up, and getting it all done in the before the timeout.
With the 500MB of disk Lambda gave us at the time we could either stash the video or the frames but not both. Sweet as, what if we skip splitting the video and do it straight in the frame processing. OK, so you want to pull the video from S3 65k times each video? Hell no. Even leaving the video in memory for warm Lambdas, the S3 costs would blow out the bill.
OK, how about stashing it on an EFS disk? This worked fine for our 2 second test video, but once we tossed a couple of full ones at it, the disk started throttling. While we could increase the IO, we kept running into the same issue.
Sweet as, Lambda’s out. ECS is the next obvious choice. Aaanndd… same issues as Lambda. Lack of enough ephemeral storage.
At this point I’d given up and had started working on getting an EC2 AMI created.
In walks an AWS SA, here for an Immersion Day the boss was running. Noticing the roughly head shaped dent in my desk, he asks how the project was going.
After unloading in a way that would make a therapist take up day drinking, he asks me “have you looked at MediaConvert?” Now, I had actually come across MediaConvert in my research. While it won’t split the video into frames, it will take stills at a set rate. All the documentation indicated that you’d be looking to only grab a frame every few seconds, with the intention of using them for promotional material or something. His response? Do it anyway. Hard to argue with that. The result was bloody epic.
This had one problem. We can only grab frames x times per second. The video that gets uploaded is recorded at 29.38 FPS (or something equally not easily divisible by a round number) and I’d previously been informed that the telemetry is at the same rate. It’s at this point the dev on the project pipes up “actually, the telemetry is at 30 FPS, it’s just that it’s close enough to the video that I’ve been treating it as one-for-one.”
Office supplies may or may not have been thrown at this point. Reports vary.
Hacking away at it for a bit longer, we managed to get the whole process down to about five minutes. Fuck yeah. Even more fine tuning, ripping out unnecessary functionality, and decreasing the processed frame rate to 5 FPS (we didn’t actually need to process every frame) we were able to get a video through at 1:40ish at the fastest.
Now of course as additional functionality got added, that time’s blown out again. But still nowhere near the original 6 hours it used to take.
If you’re interested in reading more checkout the boss’s write up. There’s also a This Is My Architecture on Youtube. Otherwise continue on for how to get something similar up and running.
Something Similar
First thing we’re going to do is create a Terraform module to handle Lambda function creation. This is because we’re going to be
using a few of them and they get real repetitive. In modules/lambda_function/main.tf
variable "environment_variables" {
description = "Dict of environment variables to attach to the Lambda function"
default = null
}
variable "function_name" {
description = "Name of the Lambda function and related resources"
}
variable "handler" {
description = "Function entrypoint"
}
variable "iam_policy" {
description = "IAM policy to attach to the Lambda Function in JSON"
}
variable "runtime" {
description = "Lambda Runtime to deploy"
}
variable "source_dir" {
description = "Directory for the Lambda Functions source code"
}
variable "timeout" {
description = "Time in seconds before the Lambda function will end with a failed state"
default = 3
}
resource "aws_iam_role" "lambda_function" {
name = var.function_name
assume_role_policy = data.aws_iam_policy_document.role.json
}
data "aws_iam_policy_document" "role" {
statement {
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
resource "aws_iam_role_policy" "lambda_function" {
name = var.function_name
role = aws_iam_role.lambda_function.id
policy = var.iam_policy
}
resource "random_uuid" "suffix" {
keepers = {
for filename in fileset(var.source_dir, "**/*") :
filename => filemd5("${var.source_dir}/${filename}")
}
}
data "archive_file" "lambda_function" {
source_dir = var.source_dir
output_path = "${path.module}/lambda-function-${var.function_name}-${random_uuid.suffix.result}.zip"
type = "zip"
}
resource "aws_lambda_function" "lambda_function" {
function_name = var.function_name
role = aws_iam_role.lambda_function.arn
filename = data.archive_file.lambda_function.output_path
runtime = var.runtime
handler = var.handler
timeout = var.timeout
dynamic "environment" {
for_each = var.environment_variables == null ? [] : [1]
content {
variables = var.environment_variables
}
}
}
output "function_arn" {
value = aws_lambda_function.lambda_function.arn
}
output "iam_role_arn" {
value = aws_iam_role.lambda_function.arn
}
This will zip the function code up, create an IAM role, and deploy the function in AWS.
Uploading a Video
Moving along to the actual ingress, we want an S3 bucket to old our videos. Back in the root of the repo:
resource "random_string" "suffix" {
length = 16
special = false
upper = false
}
resource "aws_s3_bucket" "ingress" {
bucket = "mediaconvert-test-ingress-${random_string.suffix.result}"
}
output "ingress_bucket" {
value = aws_s3_bucket.ingress.bucket
}
The random_string will be appended to required resource names to ensure uniqueness.
Let’s create the the function and link it to the S3 bucket:
data "aws_iam_policy_document" "ingress_processor_policy" {
statement {
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = ["*"]
}
}
module "ingress_processor" {
source = "./modules/lambda_function"
function_name = "ingress-processor-${random_string.suffix.result}"
handler = "lambda_function.lambda_handler"
iam_policy = data.aws_iam_policy_document.ingress_processor_policy.json
runtime = "python3.7"
source_dir = "${path.root}/lambda_functions/ingress_processor"
}
resource "aws_lambda_permission" "ingress_trigger" {
statement_id = "AllowExecutionFromS3Bucket"
action = "lambda:InvokeFunction"
function_name = module.ingress_processor.function_arn
principal = "s3.amazonaws.com"
source_arn = aws_s3_bucket.ingress.arn
}
resource "aws_s3_bucket_notification" "ingress_trigger" {
bucket = aws_s3_bucket.ingress.id
lambda_function {
lambda_function_arn = module.ingress_processor.function_arn
events = ["s3:ObjectCreated:*"]
}
depends_on = [aws_lambda_permission.ingress_trigger]
}
And our Lambda function, lambda_functions/ingress_processor/lambda_function.py:
def lambda_handler(event, context):
print(event)
At the moment our function doesn’t do much other than write the trigger event to CloudWatch so that we can see what we’re working with.
If you run terraform apply you’ll get a bucket name in the output. This is the bucket you want to upload videos to. Go ahead
now and upload a test file. It doesn’t have to be anything special.
If you leave it sit for a while you’ll eventually see a message in the Lambda functions CloudWatch Logs.
➜ aws s3 cp ingress.tf s3://mediaconvert-test-ingress-XXXXXX/video-id-here/video.mp4
upload: ./ingress.tf to s3://mediaconvert-test-ingress-XXXXXX/video-id-here/video.mp4
If you leave it sit for a while you’ll eventually see a message in the Lambda functions CloudWatch Logs.
{
"Records": [
{
"eventVersion": "2.1",
"eventSource": "aws:s3",
"awsRegion": "ap-southeast-2",
"eventTime": "2022-06-13T04:25:08.424Z",
"eventName": "ObjectCreated:Put",
"userIdentity": {
"principalId": "AWS:XXXXXXX"
},
"requestParameters": {
"sourceIPAddress": "119.224.56.196"
},
"responseElements": {
"x-amz-request-id": "XXXXX",
"x-amz-id-2": "XXXXXX"
},
"s3": {
"s3SchemaVersion": "1.0",
"configurationId": "XXXXXXXX",
"bucket": {
"name": "mediaconvert-test-ingress-XXXXXX",
"ownerIdentity": {
"principalId": "XXXXXX"
},
"arn": "arn:aws:s3:::mediaconvert-test-ingress-XXXXXX"
},
"object": {
"key": "video-id-here/video.mp4",
"size": 1418,
"eTag": "433ea94e91c11fae124bda110fab213b",
"sequencer": "0062A6BC2452A2857F"
}
}
}
]
}
The part we’re looking for is Records[].s3.object.key. This will tell us our filename.
Storing Video State
Now that we can ingress a video we need to actually process it. But before that we’re going to need somewhere to store details about individual videos.
resource "aws_dynamodb_table" "jobs" {
name = "jobs-${random_string.suffix.result}"
billing_mode = "PAY_PER_REQUEST"
hash_key = "VideoId"
attribute {
name = "VideoId"
type = "S"
}
}
Add the following to data.aws_iam_policy_document.ingress_processor_policy to allow the function to read and write to the DB.
statement {
actions = [
"dynamodb:GetItem",
"dynamodb:BatchGetItem",
"dynamodb:Query",
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:DeleteItem"
]
resources = [aws_dynamodb_table.jobs.arn]
}
Set an environment variable in the aws_lambda_function.ingress_processor
module "ingress_processor" {
source = "./modules/lambda_function"
function_name = "ingress-processor-${random_string.suffix.result}"
handler = "lambda_function.lambda_handler"
iam_policy = data.aws_iam_policy_document.ingress_processor_policy.json
runtime = "python3.7"
source_dir = "${path.root}/lambda_functions/ingress_processor"
environment_variables = {
"JOBS_TABLE" = aws_dynamodb_table.jobs.name
}
}
Finally update the Ingress Lambda Function to save the job.
import boto3
import os
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(os.environ.get('JOBS_TABLE'))
def lambda_handler(event, context):
for record in event['Records']:
filename = record['s3']['object']['key']
video_id = '/'.join(filename.split('/')[:-1])
table.update_item(
Key={'VideoId': video_id},
UpdateExpression='SET ' +
'IngressVideoBucket= :ingress_video_bucket,' +
'IngressVideoKey= :ingress_video_key',
ExpressionAttributeValues={
':ingress_video_bucket': record['s3']['bucket']['name'],
':ingress_video_key': filename
}
)
And if we upload a new file, same as before, we can see it in Dynamo:
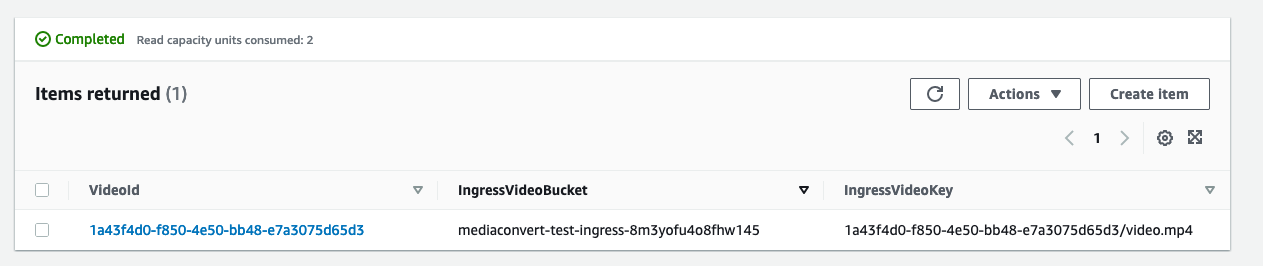
Working Directories
We need some S3 buckets before we can continue. A couple to store frames in and one to stash the output.
resource "aws_s3_bucket" "raw_frames" {
bucket = "mediaconvert-test-raw-frames-${random_string.suffix.result}"
}
resource "aws_s3_bucket" "processed_frames" {
bucket = "mediaconvert-test-processed-frames-${random_string.suffix.result}"
}
resource "aws_s3_bucket" "egress" {
bucket = "mediaconvert-test-egress-${random_string.suffix.result}"
}
MediaConvert IAM Role
Before we can kick off a MediaConvert job, we need an IAM role to grant it access to our resources.
resource "aws_iam_role" "mediaconvert" {
name = "mediaconvert-${random_string.suffix.result}"
assume_role_policy = data.aws_iam_policy_document.mediaconvert_role.json
}
resource "aws_iam_role_policy" "mediaconvert" {
name = aws_iam_role.mediaconvert.name
role = aws_iam_role.mediaconvert.id
policy = data.aws_iam_policy_document.mediaconvert_policy.json
}
data "aws_iam_policy_document" "mediaconvert_role" {
statement {
principals {
type = "Service"
identifiers = ["mediaconvert.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
data "aws_iam_policy_document" "mediaconvert_policy" {
statement {
actions = [
"s3:Get*",
"s3:List*"
]
resources = ["${aws_s3_bucket.ingress.arn}/*"]
}
statement {
actions = [
"s3:Put*"
]
resources = ["${aws_s3_bucket.raw_frames.arn}/*"]
}
}
Creating a MediaConvert Job
MediaConvert jobs are submitted by a very long JSON file. Writing this file from scratch will suck, so we’re going to submit a job via the console and export the JSON.
Browse to the MediaConvert console and click on GetStarted.
Toss the URL of your test video sitting in S3.
On the left add an Output Group. This should be a File Group. Set the output S3 URL, this’ll be our raw frames bucket.
Open up the H.264 output and enter 5000000 in the Max bitrate.
Go back up to the File Group and click on Add Output. Open up Output 2, Audio 1, and click on Remove Audio. Change the Container to “No container” and the Video Codec to “Frame Capture to JPEG” Enter 30/1 in the Frame Rate.
Back to the left, click on AWS Integration. Ensure “Use an existing service role” is selected and paste in the ARN or the IAM role created in the previous step.
You should now be good to click on Create in the bottom right.
Once the job is complete, open it up and click on View JSON in the top right. We’re going to edit this a bit and save it into
lambda_functions/ingress_processor/mediaconvert_job.json.tpl
Remove everything wrapping around the Settings value until it is the root of the file. Replace the value of
OutputGroups.OutputGroupSettings.FileGroupSettings.Destination with ${output_path} and the value of Inputs[0].FileInput
with ${input_path}.
Back in our Ingress Lambda Function
import boto3
import json
import os
from string import Template
dynamodb = boto3.resource('dynamodb')
mediaconvert = boto3.client('mediaconvert')
mediaconvert_endpoints = mediaconvert.describe_endpoints()
mediaconvert = boto3.client('mediaconvert', endpoint_url=mediaconvert_endpoints['Endpoints'][0]['Url'])
table = dynamodb.Table(os.environ.get('JOBS_TABLE'))
frames_bucket = os.environ.get('FRAMES_BUCKET')
mediaconvert_role = os.environ.get('MEDIACONVERT_ROLE')
def lambda_handler(event, context):
for record in event['Records']:
filepath = record['s3']['object']['key']
video_id = '/'.join(filepath.split('/')[:-1])
input_bucket = record['s3']['bucket']['name']
input_path = f's3://{input_bucket}/{filepath}'
output_path = f's3://{frames_bucket}/{video_id}/'
job_config = {
'input_path': input_path,
'output_path': output_path
}
with open('./mediaconvert_job.json.tpl', 'r') as f:
src = Template(f.read()).substitute(job_config)
job = json.loads(src)
res = mediaconvert.create_job(
Role=mediaconvert_role,
Settings=job,
UserMetadata={
'videoId': video_id,
'task': 'GENERATE_FRAMES'
}
)
mediaconvert_job_id = res['Job']['Id']
table.update_item(
Key={'VideoId': video_id},
UpdateExpression='SET ' +
'IngressVideoBucket= :ingress_video_bucket,' +
'IngressVideoKey= :ingress_video_key,' +
'MediaConvertJobId= :mediaconvert_job_id',
ExpressionAttributeValues={
':ingress_video_bucket': record['s3']['bucket']['name'],
':ingress_video_key': filepath,
':mediaconvert_job_id': mediaconvert_job_id
}
)
And finally update our Terraform to add the additional environment variables and permissions.
data "aws_iam_policy_document" "ingress_processor_policy" {
...
statement {
actions = [
"mediaconvert:CreateJob",
"mediaconvert:DescribeEndpoints"
]
resources = ["*"]
}
statement {
actions = [
"iam:PassRole"
]
resources = [aws_iam_role.mediaconvert.arn]
}
}
module "ingress_processor" {
...
environment_variables = {
"FRAMES_BUCKET" = aws_s3_bucket.raw_frames.bucket
"JOBS_TABLE" = aws_dynamodb_table.jobs.name
"MEDIACONVERT_ROLE" = aws_iam_role.mediaconvert.arn
}
}
If you kick off a video now, you’ll see some output getting spit out into the Frames bucket.
Handling MediaConvert Success
One thing we need to now is how manu frames we’re going to end up with so we can keep track of progress. Unfortunately, due to how we’re extracting them, there’s no easy way to get this information out of the video in advance. So what we need to do is count the number of frames in the S3 bucket after MediaConvert has finished. This’ll be done via a Lambda Function we’re going to Trigger off an EventBridge event.
resource "aws_cloudwatch_event_rule" "mediaconvert_success" {
name = "mediaconvert-success-${random_string.suffix.result}"
description = "Trigger for when a MediaConvert job finishes"
event_pattern = <<-EOF
{
"source": [
"aws.mediaconvert"
],
"detail-type": [
"MediaConvert Job State Change"
],
"detail": {
"status": [
"COMPLETE"
]
}
}
EOF
}
resource "aws_cloudwatch_event_target" "mediaconvert_success_handler" {
rule = aws_cloudwatch_event_rule.mediaconvert_success.name
target_id = "LambdaFunction"
arn = module.mediaconvert_success_handler.function_arn
}
resource "aws_lambda_permission" "mediaconvert_success_handler" {
statement_id = "AllowExecutionFromEventBridge"
action = "lambda:InvokeFunction"
function_name = module.mediaconvert_success_handler.function_arn
principal = "events.amazonaws.com"
source_arn = aws_cloudwatch_event_rule.mediaconvert_success.arn
}
module "mediaconvert_success_handler" {
source = "./modules/lambda_function"
function_name = "mediaconvert-success-handler-${random_string.suffix.result}"
handler = "lambda_function.lambda_handler"
iam_policy = data.aws_iam_policy_document.mediaconvert_success_handler.json
runtime = "python3.8"
source_dir = "${path.root}/lambda_functions/mediaconvert_success_handler"
timeout = 60 # This may need to be adjusted depending on max video length and framerate
environment_variables = {
"JOBS_TABLE" = aws_dynamodb_table.jobs.name
"PROCESSED_FRAMES_BUCKET" = aws_s3_bucket.processed_frames.bucket
"RAW_FRAMES_BUCKET" = aws_s3_bucket.raw_frames.bucket
}
}
data "aws_iam_policy_document" "mediaconvert_success_handler" {
statement {
actions = [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
]
resources = ["*"]
}
statement {
actions = [
"s3:ListBucket"
]
resources = [
aws_s3_bucket.raw_frames.arn,
aws_s3_bucket.processed_frames.arn
]
}
statement {
actions = [
"dynamodb:GetItem",
"dynamodb:UpdateItem"
]
resources = [
aws_dynamodb_table.jobs.arn
]
}
}
Our input message looks like this
{
"version": "0",
"id": "8e35a40e-b5f3-cfac-4688-72345559362d",
"detail-type": "MediaConvert Job State Change",
"source": "aws.mediaconvert",
"account": "XXXX",
"time": "2022-07-03T04:30:29Z",
"region": "ap-southeast-2",
"resources": [
"arn:aws:mediaconvert:ap-southeast-2:XXXX:jobs/1656822614416-ocyvn0"
],
"detail": {
"timestamp": 1656822629927,
"accountId": "XXXX",
"queue": "arn:aws:mediaconvert:ap-southeast-2:XXXX:queues/Default",
"jobId": "1656822614416-ocyvn0",
"status": "COMPLETE",
"userMetadata": {
"videoId": "41becbca-1fd9-460b-b2b4-9c9470dc6c21",
"task": "GENERATE_FRAMES"
},
"outputGroupDetails": [
{
"outputDetails": [
{
"outputFilePaths": [
"s3://mediaconvert-test-raw-frames-8m3yofu4o8fhw145/41becbca-1fd9-460b-b2b4-9c9470dc6c21/video.mp4"
],
"durationInMs": 31664,
"videoDetails": {
"widthInPx": 1280,
"heightInPx": 720
}
},
{
"outputFilePaths": [
"s3://mediaconvert-test-raw-frames-8m3yofu4o8fhw145/41becbca-1fd9-460b-b2b4-9c9470dc6c21/video.0000949.jpg"
],
"durationInMs": 31666,
"videoDetails": {
"widthInPx": 1280,
"heightInPx": 720
}
}
],
"type": "FILE_GROUP"
}
]
}
}
We can get the Video ID from one of the output paths. In lambda_functions/mediaconvert_success_handler/lambda_function.py
import boto3
import os
dynamodb = boto3.resource('dynamodb')
s3 = boto3.client('s3')
table = dynamodb.Table(os.environ.get('JOBS_TABLE'))
raw_frames_bucket = os.environ.get('RAW_FRAMES_BUCKET')
processed_frames_bucket = os.environ.get('PROCESSED_FRAMES_BUCKET')
def get_s3_key_count(bucket_name, path, continue_token=None):
if continue_token != None:
s3_res = s3.list_objects_v2(
Bucket=bucket_name,
Prefix=path,
ContinuationToken=continue_token)
else:
s3_res = s3.list_objects_v2(
Bucket=bucket_name,
Prefix=path)
count = s3_res['KeyCount']
if s3_res['IsTruncated']:
count += get_s3_key_count(bucket_name, path, s3_res['NextContinuationToken'])
return count
def video_split_handler(event):
video_id = event['detail']['userMetadata']['videoId']
mediaconvert_status = event['detail']['status']
total_frames = get_s3_key_count(raw_frames_bucket, video_id) - 1 # subtracting the video file
table.update_item(
Key={'VideoId': video_id},
UpdateExpression='SET MediaConvertStatus= :mediaconvertStatus, TotalFrames= :totalFrames',
ExpressionAttributeValues={':mediaconvertStatus': mediaconvert_status, ':totalFrames': total_frames}
)
def lambda_handler(event, context):
if event.get('detail', {}).get('userMetadata', {}).get('task') == 'GENERATE_FRAMES':
return video_split_handler(event)
From here, toss a video into the ingress bucket (remember to include a video ID directory) and watch it get ripped to pieces.
Wrapping Up
With that we have an S3 bucket we can toss videos into. They’ll automatically get picked up and run through MediaConvert. Individual frames will be dumped out into another S3 bucket, from which they can be processed further.
The biggest takeaway for me was to never just skip over a potential solution simply because it doesn’t look to be designed for your purpose. Everything is a hammer if you’re game enough.
If you’re having difficulty following allow, you can find a working copy on my GitHub.